Most CI pipelines don't actually know which parts of your system a change touches. They approximate it, and that approximation breaks as your repository grows.
Here's what's happening, why it matters, and how a causal model of your system changes everything.
1) Most CI pipelines don't actually know which parts of the system a change touches
They approximate it.
Path filters are the most common approach. You write rules like "if anything in src/ changes, run the tests." But what if you change a comment in src/utils.ts? The tests still run, even though nothing functional changed. What if you change a README? Your path filter might not catch that it affects documentation builds, or it might run tests that have nothing to do with documentation.
Glob patterns are slightly more sophisticated, but they're still guessing. **/*.ts tells you "some TypeScript file changed," but it doesn't tell you which tests depend on that file, which build steps need to re-run, or which Docker images are affected.
Hand-maintained dependency maps are the most accurate of the approximation methods, but they're brittle. Someone adds a new import, forgets to update the map, and suddenly your CI is missing regressions. Or worse, it's running unnecessary work because the map says something depends on a file when it actually doesn't anymore.
It "works" until the repo grows and the heuristics drift from reality. A small team can maintain these approximations. A larger codebase with hundreds of files, dozens of services, and complex interdependencies? The approximations become noise.
2) When CI guesses wrong, you pay twice
Wasted compute when it re-runs jobs that don't need to run. You changed a single comment, but CI runs your entire test suite because a path filter matched. You're burning minutes (or hours) of compute time, developer wait time, and money on work that produces no new information.
Missed regressions when it doesn't run what's affected. Your dependency map says src/api.ts doesn't affect integration tests, but you just added a new API endpoint that those tests should verify. CI skips the tests, you merge, and production breaks.
Scaling runners or parallelism doesn't fix this. It just accelerates the guesswork. You're running more guesses in parallel, but they're still guesses. You're spending more money to be wrong faster.
3) Caching is built on the same guesses
Most restore_keys strategies are really: "Hope this directory name means the same work as last time."
- uses: actions/cache@v3
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}- uses: actions/cache@v3
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}This says: "If package-lock.json has the same hash, assume ~/.npm contains the same dependencies." But what if the environment changed? What if a transitive dependency was updated outside of package-lock.json? What if the Node version changed? The cache key doesn't know.
The real identity of a computation depends on all the factors that could affect its output: the inputs it reads, the code it executes, and the environment it runs in. Anything less is a lossy proxy. A file hash is a proxy. A directory name is a proxy. A manually maintained dependency graph is a proxy. They work until they don't, and when they fail, you either waste time re-computing or ship broken code.
4) A causal model of your system changes this
Instead of guessing what changed, you observe which capabilities a computation actually touches.
Those observations define the graph. Not a hand-maintained map that drifts over time. Not a path filter that matches too broadly. A graph that's built from actual execution: "When I ran this test, it exercised these capabilities (files, services, environment) and produced these outputs."
A causal model tracks the actual dependencies between inputs, system state, and outputs:
The system state captures the complete causal identity: all inputs, code, and environment that produced a given output. When any input changes, the graph knows exactly which outputs are affected. No guessing required.
Now CI can:
Re-run only the affected nodes. If
src/utils.tschanged, the graph knows exactly which tests import it, which build steps depend on it, and which services use it. No guessing. No false positives.Reuse results where the causal path is identical. If nothing in the dependency chain changed (not the inputs, not the code, not the environment), the previous result is still valid. The graph knows this because it tracked the actual causal dependencies, not approximations.
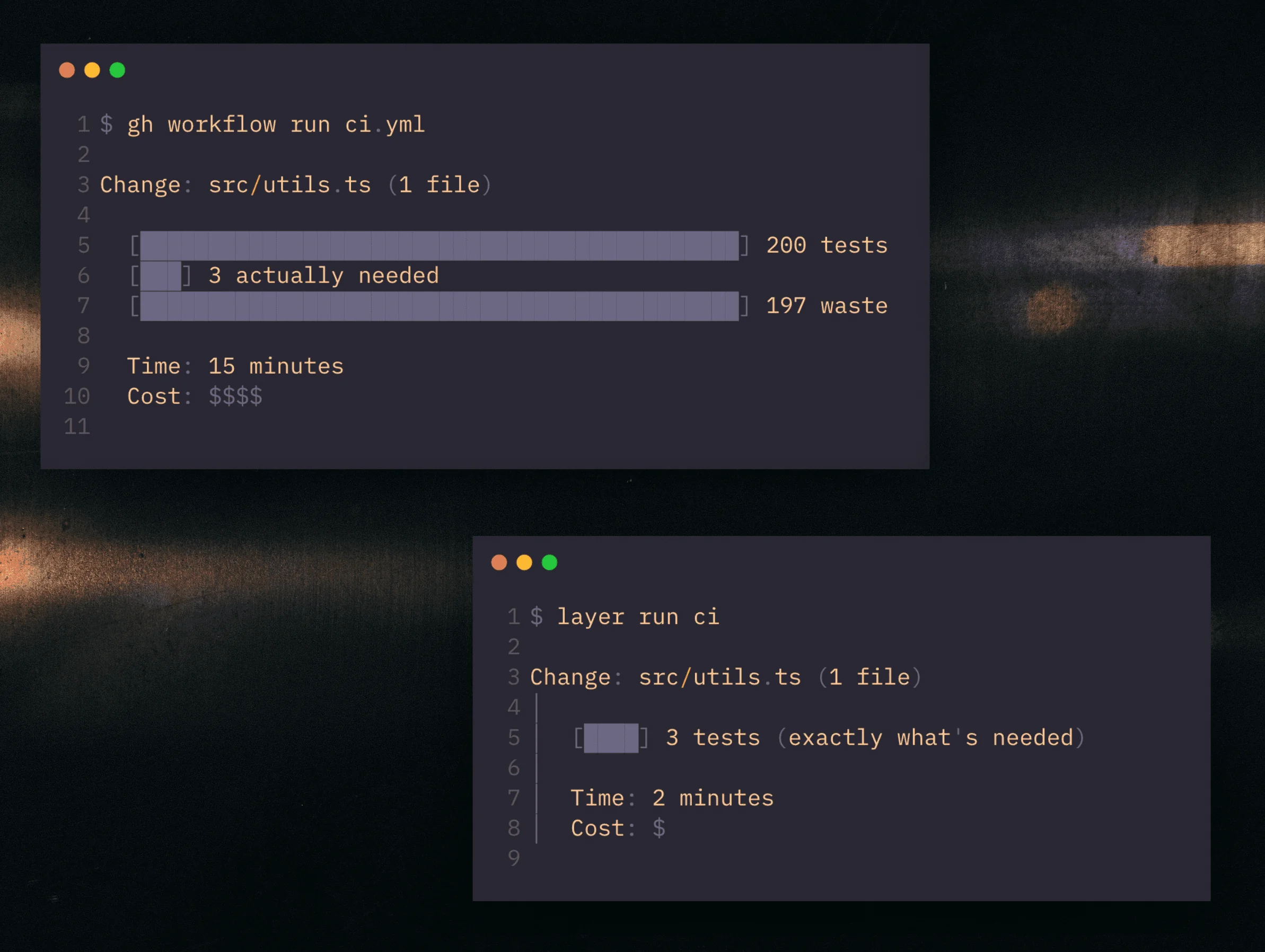
This isn't theoretical. Systems that track actual execution traces can achieve very high cache hit rates and run only the work that's actually affected by a change. The difference between a 15-minute CI run and a 2-minute one isn't just speed. It's the difference between guessing and knowing.
5) CI stops being a giant if/else tree of heuristics
It becomes a client of a graph that knows:
"Given this exact change, which parts of the world are causally downstream?"
That's the difference between guessing what changed and knowing it.
Path-based filters (what we have now):
'/api/*' ?"}:::decision Q2{"Path matches
'/schema/*' ?"}:::decision SK[Skip Pipeline]:::bad IG[Ignore Change]:::bad TR[Trigger Build]:::good %% Edges C --> Q1 Q1 -- No --> SK Q1 -- Yes --> Q2 Q2 -- No --> IG Q2 -- Yes --> TR %% Styles %% Styles - Outline style with high contrast %% Transparent fills with thick strokes - colors will be overridden by CSS for theme adaptation %% Using neutral color as base, CSS will apply white in dark mode and black in light mode classDef start fill:transparent,stroke:#999999,stroke-width:3px,color:#999999,rx:8,ry:8,font-weight:bold; classDef decision fill:transparent,stroke:#999999,stroke-width:3px,color:#999999,font-weight:bold; classDef bad fill:transparent,stroke:#999999,stroke-width:3px,color:#999999,rx:5,ry:5,font-weight:bold; classDef good fill:transparent,stroke:#999999,stroke-width:3px,color:#999999,rx:5,ry:5,font-weight:bold;
This is the decision tree that path-based CI creates: a series of if/else checks that guess what changed based on file paths. It "works" until the heuristics drift from reality.
Change detected in: src/utils.ts
→ Check path filters
→ Matches "src/**" → Run all tests
→ Matches "**/*.ts" → Run TypeScript build
→ No match for "docs/**" → Skip documentation
→ Result: Ran 200 tests, only 3 were actually affectedChange detected in: src/utils.ts
→ Check path filters
→ Matches "src/**" → Run all tests
→ Matches "**/*.ts" → Run TypeScript build
→ No match for "docs/**" → Skip documentation
→ Result: Ran 200 tests, only 3 were actually affectedCausal graph (what we should have):
Change detected in: src/utils.ts
→ Query graph: What depends on src/utils.ts?
→ tests/unit/utils.test.ts (imports it)
→ src/api/handlers.ts (calls it)
→ tests/integration/api.test.ts (tests handlers.ts)
→ Result: Ran 3 tests, all were actually affectedChange detected in: src/utils.ts
→ Query graph: What depends on src/utils.ts?
→ tests/unit/utils.test.ts (imports it)
→ src/api/handlers.ts (calls it)
→ tests/integration/api.test.ts (tests handlers.ts)
→ Result: Ran 3 tests, all were actually affectedThe graph knows because it observed the actual dependencies during previous runs. It's not guessing based on file paths or manual configuration. It's answering a precise question: "What is causally downstream of this change?"
The path forward
Most CI systems today are built on approximations because that's what was feasible when they were designed. But we have better options now. We can track actual execution. We can build causal graphs. We can know instead of guess.
The question isn't whether this is possible. It's whether we're willing to move beyond the approximations that have become "normal."
If your CI is slow, flaky, or expensive, it's probably because it's guessing. And guessing breaks at scale.
That's why I'm building Layerun, a system that knows what changed instead of guessing. But regardless of which tool you use, the principle is the same: move from approximations to observations, from heuristics to causality.
This model doesn't just apply to CI. Once you have a causal, incremental engine, CI is just one workload on a more general compute fabric.
Your CI should know what it's doing, not hope it's doing the right thing.